
您真的懂了移动机器人是怎么构建地图的吗?
1、前言
假如,您现在已经拥有一辆ROS小车了,您已经完成了通过ROS节点发布的/cmd_vel话题控制小车的基本运动了。当然,这些都是底层部分,您也许还需要完成移动机器人的建图和导航工作。本篇文章以激光SLAM算法gmapping为例,向大家介绍移动机器人构建环境地图的必备条件、算法流程、算法原理。
其实,使用gmapping算法实现建图的步骤十分简单,一般分为了解算法、安装算法、更改参数、执行算法、保存地图。各大博客,ros_wiki都有详细的流程,基本一路上不会遇到什么问题,而且还会有良好的建图效果。在您完成SLAM建图的欣喜时,您是否想过,算法的原理是什么?算法的流程是什么?如果没有或者是想了又没想清楚,那你一定要向下读,仔细读,不懂的地方查资料也要搞清楚。如有表达错误或者表达不清楚,还请大佬指教。
2、gmapping功能包的使用(懂的直接跳过本节就好)
声明:为什么选择gmapping当做例子介绍,因为经典,能说明问题。
2.1、了解算法Gmapping是一个基于2D激光雷达使用RBPF(Rao-Blackwellized Particle Filters)算法完成二维栅格地图构建的SLAM算法。
优点:gmapping可以实时构建室内环境地图,在小场景中计算量少,且地图精度较高,对激光雷达扫描频率要求较低。
缺点:随着环境的增大,构建地图所需的内存和计算量就会变得巨大,所以gmapping不适合大场景构图。一个直观的感受是,对于200x200米的范围,如果栅格分辨率是5cm,每个栅格占用一个字节内存,那么每个粒子携带的地图都要16M的内存,如果是100粒子就是1.6G内存。
2.2、安装算法ROS提供了gmapping算法功能包,这大大减少了大家使用该算法的难度,通过如下命令即可完成算法的二进制安装,前提是你已经安装了ROS。
二进制方式安装gmapping算法功能包
sudo apt-get install ros-kinetic-gmapping #根据您ROS的版本,自行更改即可关于gmapping 算法功能包中的话题和服务如下图所示:

从上图可以看出,gmapping需要订阅机器人关节变换话题/tf和激光雷达扫描数据话题/scan,将会发布栅格地图话题/map。
关于/tf又分为两个部分,gmapping功能包中的TF变换如下图所示:

所以,从上面的介绍我们就知道,gmapping算法的必备条件,/tf、/odom、/scan,就可以通过算法发布/map了。如果您的机器人还不能满足该算法的必备条件,或者不懂/tf、/odom如何获得,可以看一下我之前写的文章。关于/scan根据各自的激光雷达而定。
https://blog.csdn.net/zhao_ke_xue/article/details/108396430
https://blog.csdn.net/zhao_ke_xue/article/details/108425922
在启动gmapping算法之前,启动ROS小车以及激光雷达传感器之后,你的TF树应该大致如下图所示,这样才能满足启动gmapping算法的必备条件,也就是上面所说的内容。
使用下面命令查看tf树。
rosrun rqt_tf_tree rqt_tf_tree
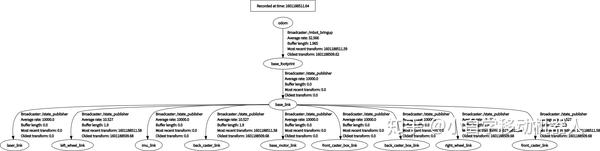
2.3、更改参数启动算法的gmapping.launch文件如下,这里需要根据各自的情况,对下面文件中注释的部分进行更改,更改内容根据自己的情况。
该启动的launch文件放在任意一个功能包的launch的文件夹中都可以,也可以新建一个功能包,因为按照二进制方式安装gmapping算法是没有这个文件的。
<
launch>
>
/>/>/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
</
node>
</
launch>2.4、启动算法使用下面的命令,即可启动gmapping算法,前提是已经启动了小车及传感器,发布了tf、odom、scan。
roslaunch robot_test gmapping.launch #这里的gmapping.launch放在robot_test功能包下在启动gmapping算法功能包之后,你的TF树应该大致如下图所示:
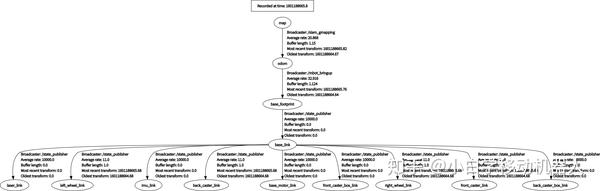
此时,在运行的ROS节点关系如下图所示,其中/mbot_bringup为手写的功能包节点主要用来发布TF和odom以及与下位机通信。
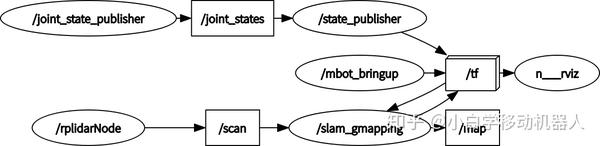
2.5、保存地图保存地图命令
rosrun map_server map_saver -f map生成map.pgm map.yaml两个文件,其中map.yaml文件内容如下:
image: map.pgm #图像文件名字
resolution: 0.050000 #图像分辨率
origin: [-13.800000, -1.000000, 0.000000] #机器人在开始建图时在地图图片上的姿态
negate: 0 #对立面
occupied_thresh: 0.65 #被占据的临界值
free_thresh: 0.196 #自由状态的临界值其实,我感觉几乎所有的同学都可以顺利的完成以上的所有内容,不然你也不会看到这篇文章。是不是感觉很空,准备条件都懂,算法安装使用都清楚、地图质量还算可以,总感觉缺点什么。对,就是算法本身,我们对算法本身还没有一点了解。所以,继续看。
3、gmapping的前世今生
声明:为了不影响描述的连贯性,对文中一些理论内容没有进行解释,这些内容将在附录里进行详细解释,不懂的地方可以查看附录。
3.1、SLAM问题的概率描述--前世首先,一个完整的SLAM问题是在给定传感器数据的情况下,同时进行机器人位姿和地图的估计的问题。然而,现实的情况是这样的,如果需要得到一个精确的位姿需要与地图进行匹配,如果需要得到一个好的地图需要有精确的位姿才能做到,显然这是一个相互矛盾的问题。
3.1.1、SLAM问题概率描述概率描述如下式(3.1):显然是一个条件联合概率分布
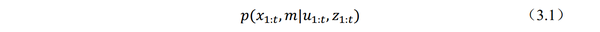
用在移动机器人从开机到t时刻一系列传感器测量数据z1:t(这里当然是/scan)以及一系列控制数据u1:t(这里认为是/odom)的条件下,同时对地图m、机器人轨迹状态x1:t进行的估计来描述SLAM问题。
3.1.2、SLAM问题分解FastSLAM算法独辟蹊径,采用RBPF方法,将SLAM算法分解成两个问题。一个是机器人定位问题,另一个是已知机器人位姿进行地图构建的问题。分解过程的公式推导如下式(3.2)
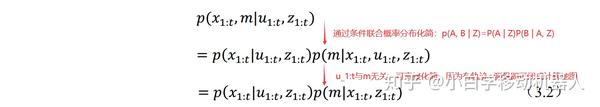
其中p(x1:t | u1:t, z1:t)表示估计机器人的轨迹,p(m|x1:t, z1:t) 表示在已知机器人轨迹和传感器观测数据情况下,进行地图构建的闭式计算。这样 SLAM 问题就分解成两个问题。其中已知机器人位姿的地图构建是个简单问题,所以机器人位姿的估计是一个重点问题。
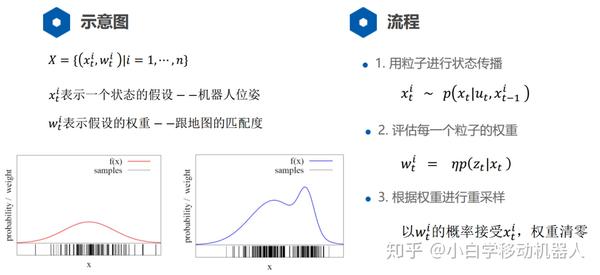
3.1.3、机器人轨迹增量估计分解FastSLAM算法采用粒子滤波来估计机器人的位姿,并且为每一个粒子构建一个地图。所以,每一个粒子都包含了机器人的轨迹和对应的环境地图。 现在我们着重研究一下 p(x1:t | u1:t, z1:t) 估计机器人的轨迹 。 通过使用贝叶斯准则对 p(x1:t | u1:t, z1:t) 进行公式推导如式(3.3)所示 :

经过上面的公式推导,这里将机器人轨迹估计转化成一个增量估计的问题,用p(x1:t-1 | u1:t-1, z1:t-1) 表示上一时刻的机器人轨迹,用上一时刻的粒子群表示。每一个粒子都用运动学模型p(xt | xt-1, ut)进行状态传播,这样就得到每个粒子对应的预测轨迹 。对于每一个传播之后的粒子,用观测模型p(zt | xt)进行权重计算归一化处理,这样就得到该时刻的机器人轨迹。之后根据估计的轨迹以及观测数据进行地图构建。
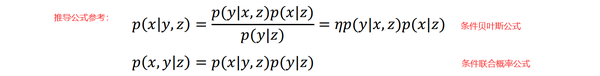
3.1.4、SLAM问题形象化描述根据上面的公式推导,我们必须整理出一个流程出来,只有这样我们才能更加清晰的理解它们。
这里以一个粒子为例,每个粒子都携带这上一时刻的位姿、权重、地图。
通过公式(3.3)我们可以看出根据上一时刻机器人轨迹通过里程计的状态传播之后,我们得到了该粒子的预测位姿。
根据预测位姿在观测模型的作用下,我们得到了该粒子代表的当前机器人轨迹,也就是完成了该粒子的机器人位姿估计。
通过公式(3.2)根据机器人轨迹结合观测数据,即可闭式得到该粒子代表的地图。
这样每一个粒子都存储了一个机器人轨迹,以及一张环境地图。
仔细理一理,是不是有点概念了。
3.1.5、总结到这里,我感觉对SLAM的问题的概率描述已经十分明了了,大家应该明确了SLAM的关键问题是机器人轨迹的估计问题,对运动模型(里程计)、观测模型(激光雷达)的角色也应该也有了更加深入的把握。然而,这不是问题的终结,而是问题的开端。继续看。
3.2、从论文看gmapping算法--今生从上一节的描述上面我们已经知道SLAM问题被分解成了两个问题,机器人轨迹估计问题和已知机器人轨迹的地图构建问题。FastSLAM算法中的机器人轨迹估计问题使用的粒子滤波方法。由于使用的是粒子滤波,将不可避免的带来两个问题。第一个问题,当环境大或者机器人里程计误差大时,需要更多的粒子才能得到较好的估计,这时将造成内存爆炸;第二个问题,粒子滤波避免不了使用重采样,以确保当前粒子的有效性,然而重采样带来的问题就是粒子耗散,粒子多样性的丢失。由于这两个问题出现,导致FastSLAM算法理论上可行实际上却不能实现。针对以上问题gmapping提出了两种针对性的解决方法。也就是说gmapping是基于FastSLAM算法将RBPF方法变成了现实。
3.2.1、降低粒子数量问题由来:每一个粒子都包含自己的栅格地图,对于一个稍微大一点的环境来说,每一个粒子都会占用比较大的内存。如果机器人里程计的误差比较大,即proposal分布(提议分布)跟实际分布相差较大,则需要较多的粒子才能比较好的表示机器人位姿的估计,这样将会造成内存爆炸。
目的:通过降低粒子数量的方法大幅度缓解内存爆炸。
分析:里程计的概率模型比较平滑,是一个比较大的范围,如果对整个范围采样将需要很多的粒子,如果能找到一个位姿优值,在其周围进行小范围采样,这样不就可以降低粒子数量了嘛。
方法一:直接采用极大似然估计的方式,根据粒子的位姿的预测分布和与地图的匹配程度,通过扫描匹配找到粒子的最优位姿参数,就用该位姿参数,直接当做新粒子的位姿。如下图所示,从普通的proposal分布采样替换为用极大似然估计提升采样的质量。这也就是gmapping算法中的做法。
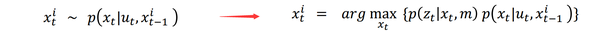
方法二:gmapping算法通过最近一帧的观测(scan),把proposal分布限制在一个狭小的有效区域。然后在正常的对proposal分布进行采样。该方法是gmapping论文中详细描述的方法。

如果proposal分布用激光匹配来表示,则可以把采样范围限制在一个比较小的区域,因此可以用更少的粒子即覆盖了机器人位姿的概率分布。也就是说将proposal分布从里程计的观测模型变换到了激光雷达观测模型。具体公式推导如下所示:

从上图可以看到激光雷达观测模型方差较小,假设其服从高斯分布,使用多元正态分布公式即可进行计算,于是求解高斯分布是下面需要做的。
同方法一,首先通过极大似然估计找到局部极值x_t,认为该局部极值距离高斯分布的均值比较近,于是在位姿x_t附近取了k个位姿;对k个位姿进行打分(位姿匹配),这样我们就具有k个位姿,以及它们与地图匹配的得分;我们又假设它们服从高斯分布,计算出它们的均值和方差之后,即可使用多元正态分布,对机器人位姿的估计进行概率计算。矢量均值和协方差的计算。具体如下式(3.4) (3.5)
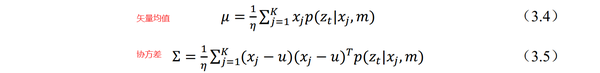
多元正态分布公式如下,可以根据均值和协方差,直接计算得出后验概率。
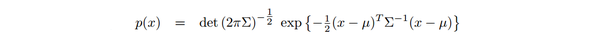
当然,这里不仅要计算每一个粒子的轨迹的后验概率,还要为每一个粒子计算权重,这里对权重具体的计算方式就不做描述了。论文里有。
3.2.2、缓解粒子耗散问题由来:gmapping算法采用粒子滤波算法对移动机器人轨迹进行估计,必然少不了粒子重采样的过程。随着采样次数的增多,会出现所有粒子都从一个粒子复制而来,这样粒子的多样性就完全丧失了。
目的:缓解粒子耗散
分析:gmapping算法从算法原理上使用粒子滤波,不可避免的要进行粒子重采样,所以,问题实实在在的存在,不能解决,只能从减少重采样的思路走。
方法:gmapping提出选择性重采样的方法,根据所有粒子自身权重的离散程度(也就是权重方差)来决定是否进行粒子重采样的操作。于是就出现了式(3.7),当Neff小于某个阈值,说明粒子差异性过大,进行重采样,否则,不进行。
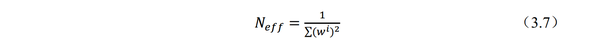
3.2.3、gmapping算法流程论文中采用以上两个针对性方法,一定程度上解决了FastSLAM算法的不现实性。下面,我们从gmapping算法的伪代码来认识它。

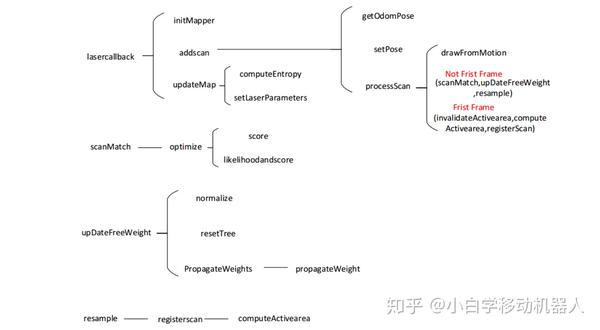
3.3、从源码看gmapping算法关于gampping算法的源码,不是一篇文章就能介绍清楚的,这里仅仅给出一个算法函数的调用流程,以后有机会,会按照模块分析源码。
4、总结
根据以上的全部内容,我们得到了什么,如果仔细读的话,你会发现gmapping算法进行地图构建的流程还是十分清晰的。不管是SLAM问题的概率描述、SLAM问题的分解、机器人位姿估计的迭代式的转变还是gmapping的算法流程,我们都可以从头到尾的分析清楚,清楚每一步是为什么,是做什么;这也就是本文的目的所在。关于gmapping源码解读,已知位姿构建地图算法,或者贝叶斯滤波、粒子滤波等等相关题材的文章,将在不就的将来陆续出现。
关于gmapping论文,带中文注释的源码,以及相关课件,在公众号发送:gmapping,即可获得。
附录:粒子滤波
从知乎上看到的一个有趣的解释。
简单来说,在机器人定位问题中,我们想要估计机器人的位置和姿态。最初,我们完全不知道机器人在哪,那就索性假设机器人以同等的概率出现在地图上的任意一个位置。比如,假如地图是整个中国,那么机器人就等可能地出现在北京、上海、广州、哈尔滨等地。于是我们就可以用一个粒子代表一个机器人可能出现的位置。现在,机器人说话了,它说它感觉特别冷,雪落在了它洁白的脖子上。于是,我当即排除了长江以南的城市,南方怎么可能下雪呢!机器人系上围脖,继续向前走。没走几步,它又抱怨道,“今天空气质量可真不怎么样,我的双目都要失明了。”显然,它是遇到了雾霾天,这种天气在北方某帝都倒是挺常见的。它点亮了IR主动光探测,雾霾天上路多加小心总没有错。转眼间,机器人来到一个庞大的建筑物面前,这里人声鼎沸,还有遍地的商贩在叫卖着不知什么东西。它借助自身廉价的激光雷达小心翼翼地在人群中穿梭。突然,它若有所思地停了下来,似乎发现了一个美丽的秘密。虽然外面寒冬凌冽,这里却如春天般富有生机,到处洋溢着绿色的海洋。人声此起彼伏,它依稀听出了五个字,“国安是冠军”...
在上面的例子中,“我”作为机器人的大脑,根据机器人的感受,可以得出如下推理。机器人发现下雪了,那么可以确定机器人应该在北方的某个城市。接着,机器人遇到了雾霾天,那么说明该城市的空气质量很差,这就进一步把搜索范围缩小到了某几个重点空气污染城市。最后,机器人听到的五个字“国安是冠军”,彻底让我锁定了它所在的城市——“北京”。
这就是一个形象的粒子滤波案例。机器人不断地通过运动、观测的方式,获取周围环境信息,逐步降低自身位置的不确定度,最终得到准确的定位结果。
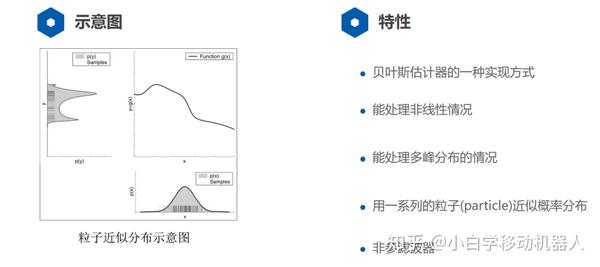
从理论上看粒子滤波。
==以往链接,点击访问。==
上一篇:ROS机器人开机自启动设置
下一篇:更新中... src="https://pic2.zhimg.com/v2-f9fa3500658d9728c19daf33b5f67729_b.jpg">

庄家第十二巡时掩牌,是非常巧妙的伪装并且实阮上是在等四、七筒,喊掩牌时,这边的手中是三、五、七条与六、八筒进中间牌的听牌,到底要拆掉哪一个呼间搭,最好是看情形而定。
在这种伏况下,如摸到二万、四条或六条,应该果断地打掉五条,成为断么·三睹碰的碰碰和的牌型。这样,即使放镜和也是很大的牌。假如能自摸和,一举使成为四暗碰的满贯。



